内容が古くなっている可能性がありますのでご注意下さい。
この連載では、オープンソースの統計解析ツール、Rを利用して統計データを解析します。今回は「クラスター分析」という手法を用いて、横浜市の18行政区を分類してみます。
クラスター分析は、データの類似性に基づいて対象をグループ(クラスター)に分ける手法です。
横浜市のように大きな自治体では、各行政区によって異なる地域課題を抱えています。そこで、区と区の類似点・相違点を知る必要があります。そのような場合に、クラスター分析は階層構造にビジュアライズすることができるため有用です。
今回は、年齢別人口、地区別宅地面積、自動車台数という異なるデータを用いて、横浜市の18行政区をクラスター化します。そうすることにより、用いるデータが異なると(すなわち分析の観点が異なると)異なる分類ができることを確認します。
はじめに、年齢別人口をクラスター分析するためのデータを用意します。横浜市統計ポータルサイトから年齢(5歳階級)別人口のExcelファイルをダウンロードします。行政区によって人口総数に大きな違いがある(最少の西区は94,867人、最多の港北区は329,471人)ため、各行政区毎に、年少人口(0~14歳)、生産年齢人口(15~64歳)、老年人口(65歳~)を総人口で割り、以下のCSVファイルを作成します。
行政区,年少人口率,生産年齢人口率,老年人口率 鶴見区,0.13041,0.68164,0.18007 神奈川区,0.11441,0.68964,0.18814 西区,0.10378,0.69873,0.18461 中区,0.10391,0.64303,0.20095 南区,0.10994,0.65647,0.22633 港南区,0.12827,0.64967,0.22190 保土ケ谷区,0.12160,0.65209,0.22095 旭区,0.12718,0.62811,0.24234 磯子区,0.11972,0.64678,0.22959 金沢区,0.12716,0.64983,0.21766 港北区,0.12436,0.70328,0.16559 緑区,0.14563,0.65867,0.19435 青葉区,0.15283,0.68753,0.15865 都筑区,0.18185,0.66640,0.13306 戸塚区,0.14340,0.65367,0.20078 栄区,0.13238,0.62287,0.24256 泉区,0.13948,0.63229,0.22476 瀬谷区,0.14442,0.62608,0.22746
データができたらRを起動します。
Rコンソールに以下のコマンドを入力します。
data <- read.csv("t021602.csv", sep=",", row.names=1)
d <- dist(data)
h <- hclust(d)
plot(h, main="年齢別人口によるクラスター分析", xlab="行政区", sub="" )
まず、read.csv()でCSVファイルを読み込み、dataという名前のオブジェクトに格納します。
次に、dataに基づく区と区の間の距離をdist()で計算し、dという名前のオブジェクトに格納します。dは以下のような距離行列になります。
,鶴見区,神奈川区,西区,中区,南区,港南区,保土ケ谷区,旭区,磯子区,金沢区,港北区,緑区,青葉区,都筑区,戸塚区,栄区,泉区,瀬谷区 鶴見区 神奈川区,0.0196 西区,0.0320,0.0144 中区,0.0513,0.0495,0.0580 南区,0.0565,0.0508,0.0597,0.0293 港南区,0.0527,0.0541,0.0663,0.0328,0.0200 保土ケ谷区,0.0512,0.0504,0.0618,0.0282,0.0136,0.0072 旭区,0.0822,0.0830,0.0942,0.0498,0.0368,0.0297,0.0326 磯子区,0.0615,0.0599,0.0705,0.0329,0.0141,0.0119,0.0103,0.0238 金沢区,0.0494,0.0512,0.0635,0.0294,0.0204,0.0044,0.0068,0.0329,0.0144 港北区,0.0267,0.0282,0.0284,0.0728,0.0780,0.0778,0.0755,0.1075,0.0855,0.0747 緑区,0.0310,0.0444,0.0587,0.0450,0.0480,0.0338,0.0364,0.0598,0.0453,0.0310,0.0572 青葉区,0.0316,0.0485,0.0566,0.0785,0.0859,0.0777,0.0782,0.1058,0.0883,0.0746,0.0333,0.0465 都筑区,0.0713,0.0901,0.0990,0.1060,0.1182,0.1051,0.1075,0.1281,0.1165,0.1021,0.0757,0.0716,0.0441 戸塚区,0.0371,0.0479,0.0621,0.0409,0.0422,0.0263,0.0297,0.0514,0.0379,0.0237,0.0637,0.0084,0.0549,0.0789 栄区,0.0858,0.0880,0.0997,0.0543,0.0435,0.0341,0.0379,0.0074,0.0300,0.0371,0.1116,0.0615,0.1079,0.1278,0.0531 泉区,0.0672,0.0725,0.0854,0.0441,0.0382,0.0209,0.0269,0.0219,0.0250,0.0226,0.0936,0.0407,0.0872,0.1066,0.0324,0.0214 瀬谷区,0.0744,0.0805,0.0936,0.0513,0.0460,0.0291,0.0352,0.0229,0.0323,0.0310,0.1009,0.0465,0.0926,0.1093,0.0384,0.0196,0.0084
例えば、瀬谷区の行を見ると、泉区との距離は0.0084で最も近く、都筑区との距離は0.1093で最も遠いことが分かります(数値が大きいほど距離が離れている)。
しかし、この行列では全体を俯瞰するのに適していませんので、hclust(d)で階層クラスタを作成します。plot()すると以下のように結果が表示されます。
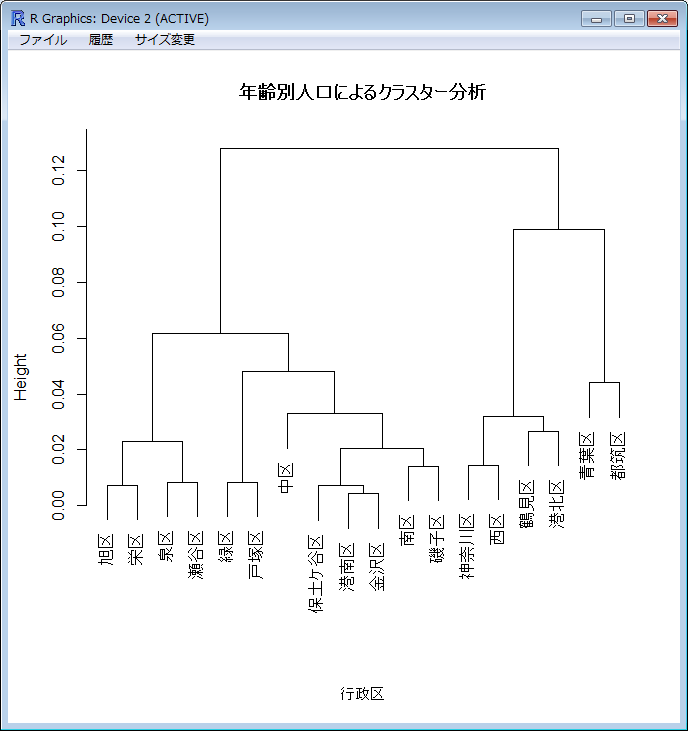
旭区から磯子区までと、神奈川区から都筑区までの2グループに大別されています。元データを見ると、前者は後者よりも生産年齢人口率が低く、老年人口率が高いことが分かります。
さらに前者は旭区から瀬谷区までのグループと緑区から磯子区のグループに、後者は神奈川区から港北区までのグループと青葉区・都筑区のグループに分かれています。
元データを見ると、青葉区と都筑区は年少人口率が高いグループであることが分かります。
クラスター分析を行なうと、各行政区の特徴を分類という形で表現することができます。
次に、地区別宅地面積によるクラスター分析をします。横浜市統計ポータルサイトから行政区別地区別宅地面積のExcelファイルをダウンロードします。行政区毎に、商業地区、工業地区、住宅地区の面積を総面積で割り、以下のCSVファイルを作成します。
行政区,商業地区,工業地区,住宅地区 鶴見区,0.04241,0.48031,0.47727 神奈川区,0.07525,0.16053,0.76380 西区,0.27003,0.03619,0.69378 中区,0.16731,0.41883,0.41386 南区,0.05779,0.00000,0.94219 港南区,0.01831,0.00000,0.98169 保土ケ谷区,0.04414,0.00280,0.95295 旭区,0.01837,0.00904,0.97240 磯子区,0.03431,0.29365,0.67186 金沢区,0.02144,0.27891,0.69951 港北区,0.07124,0.11263,0.81597 緑区,0.02886,0.04956,0.92122 青葉区,0.02176,0.01565,0.96252 都筑区,0.05507,0.17347,0.77101 戸塚区,0.02144,0.09310,0.88419 栄区,0.00708,0.08276,0.91013 泉区,0.01175,0.01291,0.97445 瀬谷区,0.03518,0.08984,0.87403
Rコンソールに以下のコマンドを入力すると、
data <- read.csv("t021602.csv", sep=",", row.names=1)
d <- dist(data)
h <- hclust(d)
plot(h, main="地区別宅地面積によるクラスター分析", xlab="行政区", sub="" )
以下の結果が表示されます。
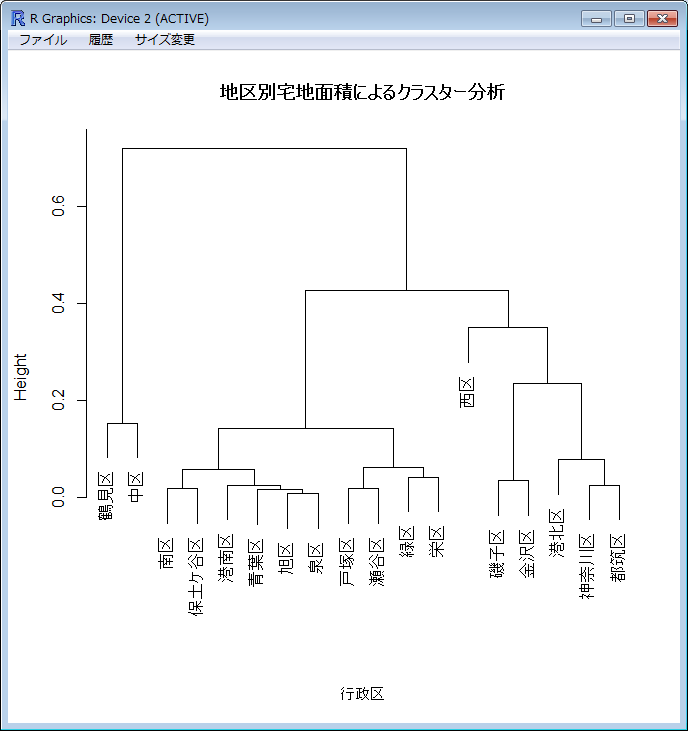
今度は、鶴見区と中区が、他の行政区とは別のグループになりました。元データを見ると、この2区だけは工業地区が4割を超えて突出していることが分かります。さらに、南区から栄区のグループと、西区から都筑区のグループに分かれています。前者は住宅地区が9割を超えているグループです。西区から都筑区のグループの中は、西区とその他に分かれていますが、このグループの中で、西区は商業地区が工業地区より多く、磯子区から都筑区は工業地区が商業地区より多いという違いがあります。
最後に、自動車台数によるクラスター分析をします。横浜市統計ポータルサイトから自動車台数のExcelファイルをダウンロードします。行政区毎に、貨物用、乗用、軽自動車の台数を総台数で割り、以下のCSVファイルを作成します。
行政区,貨物用,乗用,軽自動車 鶴見区,0.12958,0.66724,0.20318 神奈川区,0.11059,0.67227,0.21714 西区,0.10202,0.68704,0.21094 中区,0.19243,0.64456,0.16301 南区,0.07014,0.69069,0.23917 港南区,0.05197,0.73020,0.21783 保土ケ谷区,0.06709,0.69578,0.23712 旭区,0.07319,0.68902,0.23779 磯子区,0.05700,0.72617,0.21683 金沢区,0.09209,0.71124,0.19667 港北区,0.08449,0.72837,0.18714 緑区,0.05915,0.71405,0.22680 青葉区,0.03709,0.81672,0.14619 都筑区,0.10603,0.71712,0.17685 戸塚区,0.06464,0.70776,0.22761 栄区,0.04699,0.74436,0.20865 泉区,0.06838,0.67773,0.25389 瀬谷区,0.08016,0.65066,0.26919
Rコンソールに以下のコマンドを入力すると、
data <- read.csv("090800.csv", sep=",", row.names=1)
d <- dist(data)
h <- hclust(d)
plot(h, main="自動車台数によるクラスター分析", xlab="行政区", sub="" )
以下の結果が表示されます。
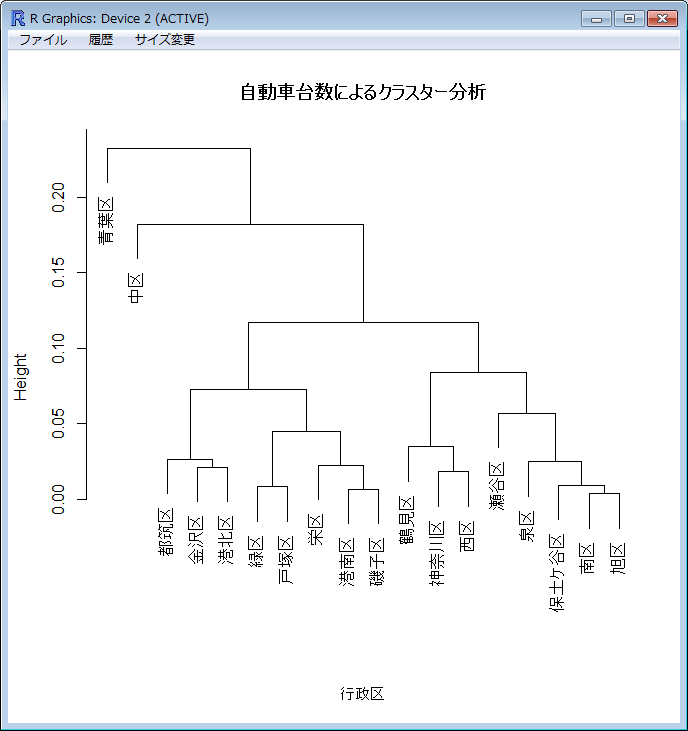
今度は、青葉区と中区が他のグループと大きく分かれる結果となりました。元データを見ると、青葉区のみ乗用車が8割を超えており、中区のみ貨物用が2割近くあるということが分かります。
以上のように、クラスター分析を用いて階層構造にビジュアライズすることによって、各行政区の類似点・相違点を知ることができます。