内容が古くなっている可能性がありますのでご注意下さい。
Darknet YOLOv4を使って機械学習を始め、「深層学習による石造物の分類」以来、いくつかのブログ記事を書いてきました。1ヶ月ほど前にYOLOv5に移行したところ、予想を遥かに上回る良好な結果を得ることができましたので、簡単にYOLOv5を紹介します。
特筆すべき点は、
- インストールが簡単(Pythonの環境があれば動作し、Visual Studioのような開発環境は不要)
- 検出処理が高速で精度も高い
です。また、YOLOv5はGPU(CUDA)なしで動作させることも可能です。
インストール
こちらのページでは以下の3ステップ
$ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ pip install -r requirements.txt
が書かれていますが、途中でPyTorch関係のエラーが出ました。そこで、
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
でPyTorchをインストールしてから、再び
pip install -r requirements.txt # install dependencies
を実行しました。
OSやCUDAのバージョンなどの環境に応じたPyTorchのインストール用コマンドはこちらのページで生成することができます。
独自データを用いた学習
学習用データ(画像ファイルとアノテーションの.txtファイル)はYOLOv4に作成したものをそのまま利用することができます。
トレーニング用とバリデーション用に以下のフォルダに9:1に振り分けました。
/yolov5/data/stone/train/
/yolov5/data/stone/valid/
重要なのはモデルの選択です。YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5xの順に大きくなる4つのモデルから選択することができます。大きなモデルは精度が高くなりますが実行速度が遅くなり、学習時に必要となるGPUメモリも増加します。
当初、YOLOv5mを使用していましたが、現在はYOLOv5sを使用しています。YOLOv5mと比べるとわずかに精度が落ちましたが、YOLOv4との比較では(学習用データが増えたことの影響もあるでしょうが)全く遜色ありません。処理速度の速さは魅力です。
学習パラメータのファイル stone.yaml は以下の内容で作成しました。
train: data/stone/train val: data/stone/valid nc: 7 names: ['stone','night','koshin','jizo','douso','nyoirin','batou']
最初の2行で学習データのフォルダを指定しています。「nc: 7」は検出するオブジェクトが7クラスであることを示し、次の「names: [‘stone’,’night’,’koshin’,’jizo’,’douso’,’nyoirin’,’batou’]」でそれらの名前を示しています。
現在のところ、以下のオブション指定で学習をさせています。
python train.py --data stone.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt --batch-size 15 --img-size 800
バッチサイズは、デフォルトの16ではCUDAがOut of Memoryになるため、1つ少なく指定しています。
画像サイズのデフォルトは640ですが、大きめの800を指定したところ精度が向上しました。
epoch数は指定せず、デフォルトの300としています。yolov5s.ptは、初回の実行時に自動的にダウンロードされます。
学習結果は runs/train の下に exp、exp2、exp3… のように毎回新しいフォルダが作成されて格納されます。以前の実行結果を誤って上書きしてしまう心配がありません。
学習済みモデルは exp(n)/weights の下に best.pt と last.pt の2つ作成されます。best.pt は最も精度の高いモデルで、last.pt は最後に作られたモデルです。
検出処理の実行
以下のコマンドで検出処理を実行します。
python detect.py --weights best.pt --img-size 800 --source (ファイル名|フォルダ名)
–weights オプションで学習済みモデルを指定します。画像サイズは学習時と同じ 800 を指定しています。検出対象が静止画像でも動画でも、–source でファイル名を指定します。フォルダ名を指定すると、そのフォルダ内のファイル全てを処理するので便利です。
検出結果は runs/detect の下に exp、exp2、exp3… のように毎回新しいフォルダが作成されて格納されます。
–save-txt オプションを付けて実行すると、アノテーションのテキストファイルを出力します。「WebクローラーでAIの学習データ収集」のようなことをする場合に便利です。
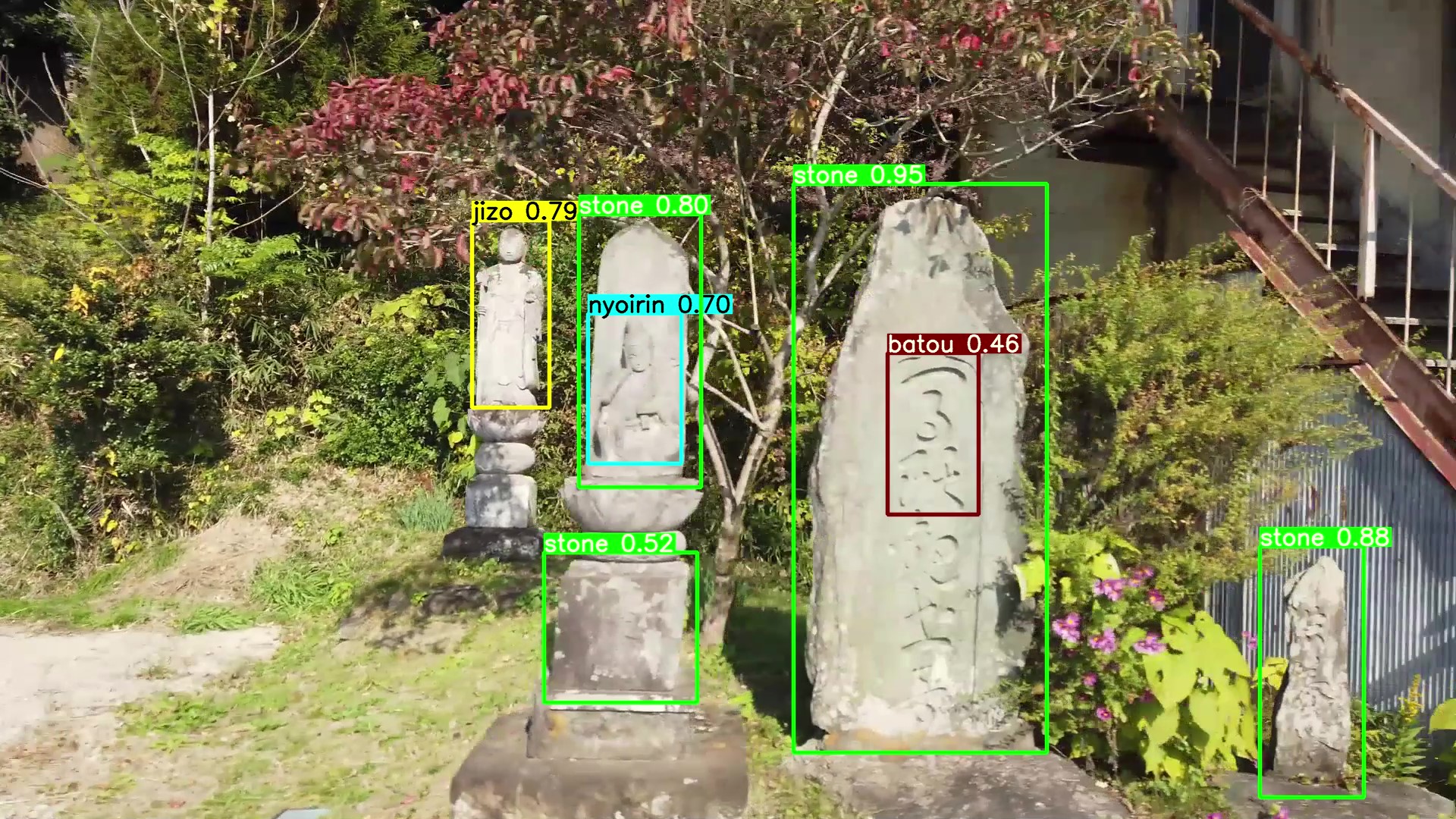
検出結果の例は「車載カメラとAIによる路傍の石造物調査記録」を御覧下さい。