内容が古くなっている可能性がありますのでご注意下さい。
「ScrapyによるWebクローラーの開発」で作成したクローラーと、「Darknet YOLOをPythonで使う」で作成したディープラーニングによる月待塔の検出(実際には、「夜」と刻まれた石造物の検出)を組み合わせて、クローリングで得られた画像から月待塔を検出します。
手順は以下のようになります。
- Webクローラで画像ファイルとその画像が貼られたページのURLの一覧をデータベースに格納する。
- 画像ファイルをダウンロードして物体検出する。
- 検出できた場合は、元画像と検出結果画像を保存し、判定結果trueと検出結果画像のファイル名をデータベースに格納する。
- 検出できなかった場合は判定結果falseをデータベースに格納する。
- 検出結果画像と、元画像の貼られたページのURLを、ブラウザに一覧表示する。
手順1.は、「ScrapyによるWebクローラーの開発」で作成したプログラムをそのまま利用します。データベースの images テーブル名には、tinyint(1) の result カラムと、可変長文字列の tmpfile カラムを追加しておきます。
手順2.は、「Darknet YOLOをPythonで使う」で作成したプログラムを改造し、元々ローカルのファイルシステム上にある画像ではなく、データベースに格納されたURLからダウンロードした画像を使用してYOLOによる物体検出をおこない、さらに結果をデータベースに格納します。
改造したプログラムは以下のとおりです。
from skimage import io
import tempfile
import MySQLdb
import urllib.request
import os
from darknet2 import performDetect
def main():
conn = MySQLdb.connect(user='scrapy', passwd='scrapy', host='localhost', db='scrapy')
conn.autocommit(True)
sql = 'SELECT DISTINCT url FROM images WHERE result IS NULL'
sql2 = 'UPDATE images SET result = true, tmpfile=%s WHERE url=%s'
sql3 = 'UPDATE images SET result = false WHERE url=%s'
c = conn.cursor()
try:
c.execute(sql)
for row in c:
if not row[0].lower().endswith('.jpg') and not row[0].lower().endswith('.jpeg'):
continue
try:
with urllib.request.urlopen(row[0]) as web_file:
data = web_file.read()
with tempfile.NamedTemporaryFile(mode='w+b', delete=False, dir="f:\\temp", suffix=".jpg") as local_file:
local_file.write(data)
local_file.close()
except urllib.error.URLError as e:
print(e)
continue
result = performDetect( imagePath=local_file.name, \
thresh= 0.25, \
configPath = "./yolo-tsukimachi.cfg", \
weightPath = "./yolo-tsukimachi.weights", \
metaPath = "./yolo-tsukimachi.data", \
showImage= True, \
makeImageOnly = True, \
initOnly= False)
if isinstance(result, list) :
continue # Maybe image file format error
moon = False
for d in result["detections"]:
if d[0] == "night":
for d2 in result["detections"]:
if d2[0] == "stone":
if( d[2][0] > d2[2][0] - d2[2][2]/2 and \
d[2][0] < d2[2][0] + d2[2][2]/2 and \
d[2][1] > d2[2][1] - d2[2][3]/2 and \
d[2][1] < d2[2][1] + d2[2][3]/2 ):
moon = True
break
if moon == True:
out = local_file.name.replace('.jpg', '-result.jpg')
io.imsave(out, result["image"])
c2 = conn.cursor()
try:
c2.execute(sql2, [out, row[0]])
except MySQLdb.Error as e:
print('MySQLdb.Error: ', e)
c2.close()
else:
try:
os.remove(local_file.name)
except:
pass
c2 = conn.cursor()
try:
c2.execute(sql3, [row[0]])
except MySQLdb.Error as e:
print('MySQLdb.Error: ', e)
c2.close()
except MySQLdb.Error as e:
print('MySQLdb.Error: ', e)
c.close()
conn.commit()
if __name__ == '__main__':
main()
上記ソースのSQL文で、’SELECT’や'UPDATE'の一文字目が全角になっているのは、ブログ投稿時にWAFでエラーになるのを防ぐためです。もちろん半角が正しいです。
画像ファイルのURL取得時に DISTINCT を付けているのは、同じ画像が複数のページからリンクされていることがあるためです。特にブログでは、月毎やカテゴリ毎のまとめページが自動的に作成されることが多くあります。
URLからダウンロードした画像をYOLOの performDetect() 関数に渡して物体検出をおこないます。検出できた場合は、performDetect() 関数から返された検出結果画像を保存します。検出できなかった場合は、ダウンロードした画像を削除しています。
手順3.の結果確認は、以下のPHPスクリプトを使用してブラウザでおこないます。'SELECT'のほか'echo'も一文字目を全角にしています。
<html>
<body>
<?php
$mysqli = new mysqli( 'localhost', 'scrapy', 'scrapy', 'scrapy');
if( $mysqli->connect_errno ) {
exit(1);
}
$res = $mysqli->query("SELECT * FROM images WHERE result = True ORDER BY url");
if (!$res) {
exit(1);
}
$current="";
while( $data = $res->fetch_assoc() ){
if( $current != $data["url"] ) {
echo '<br/><img src="' . str_replace("f:\\temp\\", "/temp/", $data["tmpfile"]) . '"/></img><br/>';
echo '<a href="' . $data["referer"] . '" target="_blank">' . $data["referer"] . '</a><br/>';
$current = $data["url"];
} else {
echo '<a href="' . $data["referer"] . '" target="_blank"/>' . $data["referer"] . '</a><br/>';
}
}
?>
</body>
</html>
imagesテーブルからすべての行を検索します。このとき、画像ファイルのURLでソートしておきます。
1行ずつ結果を取得し、画像ファイルのURLが変わったタイミングでは、検出結果画像とリンク元ページのURLを表示し、前回と同じ場合にはリンク元ページのURLのみを表示します。
今回、検出結果の画像ファイルは F:\temp ディレクトリに保存したため、仮想ディレクトリ /temp/ で参照できるよう、Apacheの設定ファイルに以下の記述を追加しました。
Alias /temp/ "F:/temp/"
<Directory "F:/temp/">
Require all granted
</Directory>
月待ビンゴプロジェクトの moon.midoriit.com を対象に実行した結果は以下のようになりました。
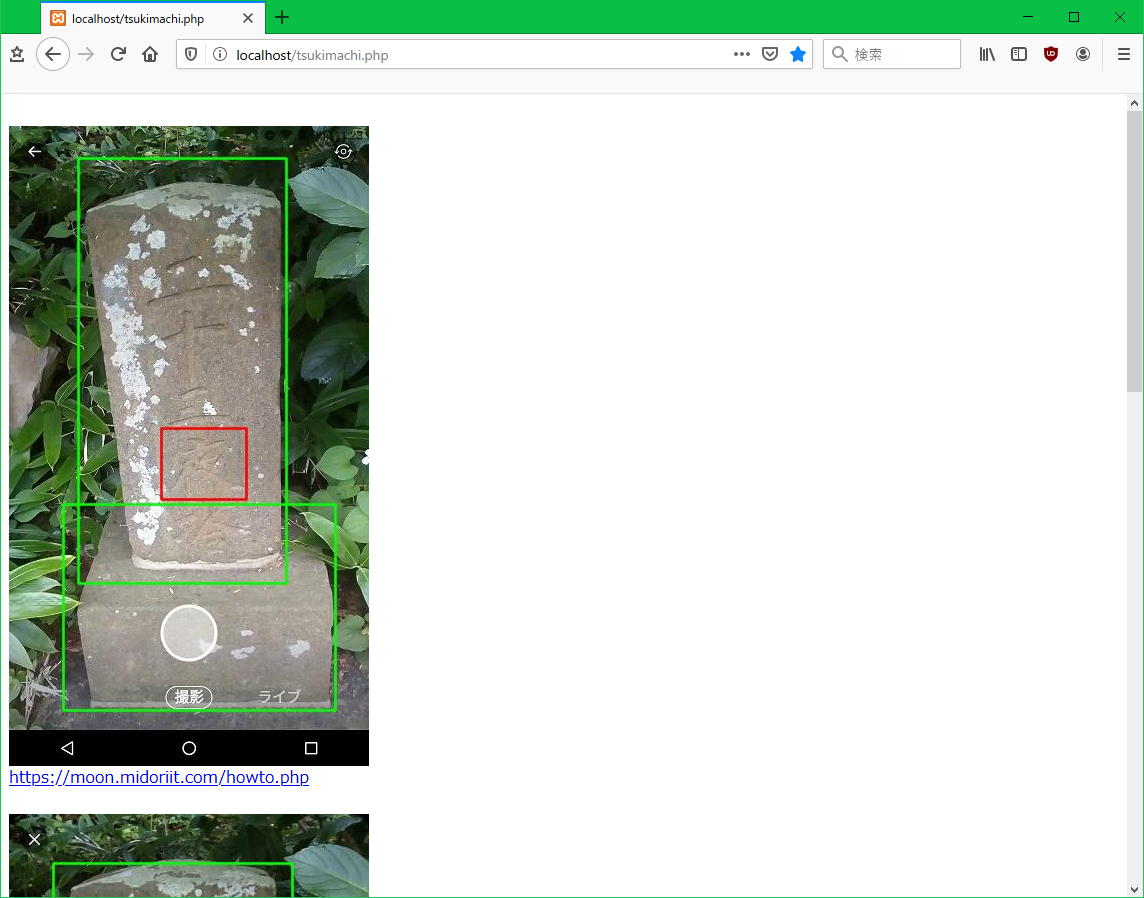
画像の下のリンクをクリックすると、オリジナルの画像が貼られたWebページが表示されるので、その画像についての情報を得ることができます。