内容が古くなっている可能性がありますのでご注意下さい。
前回はVisual Studioでビルドしたdarknet.exeを使用して、石造物に刻まれた文字の学習と検出の実験をしました。
Darknet YOLOはDLL版をビルドすることによりAPIの利用が可能になります。独自のAIアプリケーションを開発する際には、exeファイルをコマンドとして起動するよりも適しています。また、Python用のラッパーも用意されています。
そこで今回は、指定したフォルダから月待塔の写っている画像ファイルを探し出す簡単なPythonプログラムを作成することとします。
DLL版Darknetのビルド
DLL版のビルド方法については、ソースコードを公開しているGitHubに書かれています。
yolo_cpp_dll.dllとyolo_cpp_dll_nogpu.dllが必要になります。それぞれ、yolo_cpp_dll.slnとyolo_cpp_dll_no_gpu.slnを用いてビルドします。
cuda 10.2を使用しているため、yolo_cpp_dll.vcxprojとyolo_cpp_dll_no_gpu.vcxprojでcuda 10.0を参照している箇所をcuda 10.2に変更する必要がありました。
学習用データの準備
月待塔には月待行事をおこなった「アタリ日」が〇〇夜と刻まれているのが特徴です。
そこで今回は、石造物の本体と「夜」の文字を学習させ、石の中に「夜」の文字が見つかれば月待塔と判定することにします。アノテーションには、今回もマイクロソフトのVoTT(Visual Object Tagging Tool)を使用しました。
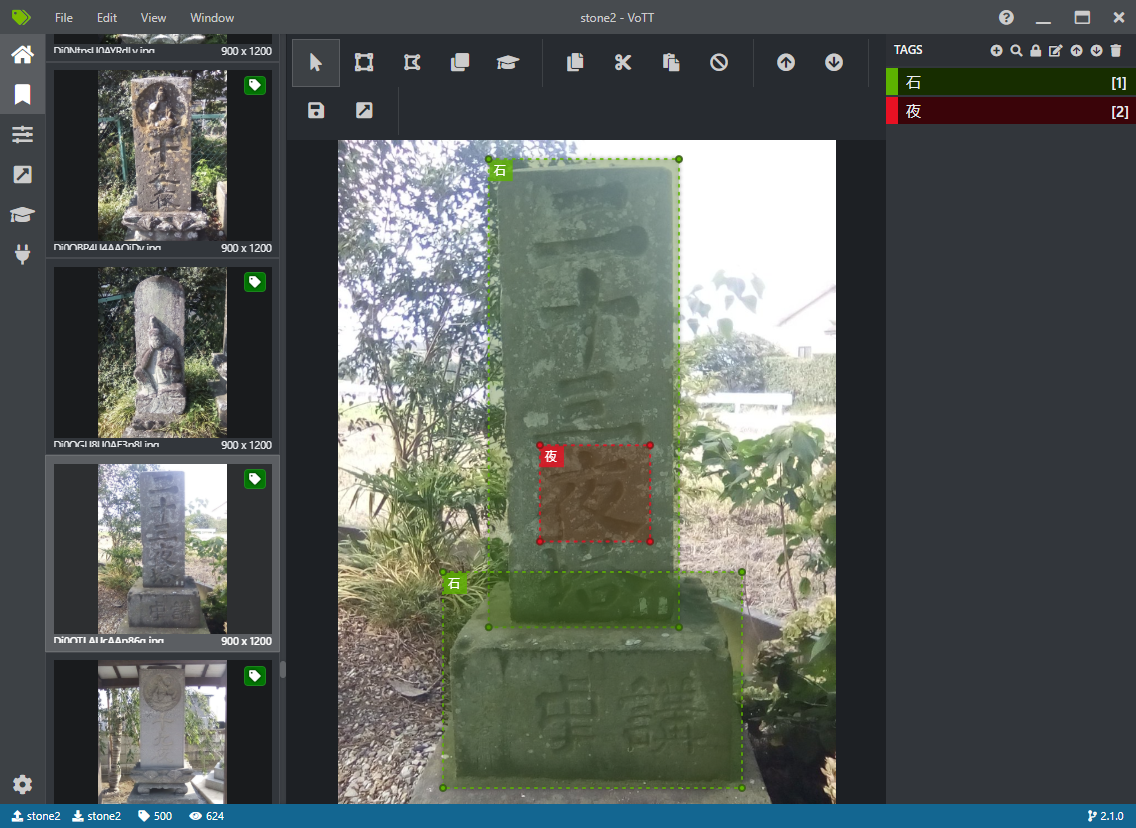
学習に使用した画像ファイルは500枚で、ラベルは
- 石 696件
- 夜 453件
でした。
上記の画像のように塔身と台石を別々にラベルを付けたり、1枚の写真に複数の石造物が写っていたりすることもあるため、石のラベルは画像の枚数よりも多くなっています。
プログラムの作成
作成したプログラムは以下のとおりです。Python用のラッパーdarknet.pyを使用することで、簡単なプログラムになりました。
import argparse
import glob
from skimage import io
from darknet import performDetect
def main():
parser = argparse.ArgumentParser(description='Find Tsukimachi-to images.')
parser.add_argument('folder', help='image folder')
args = parser.parse_args()
files = glob.glob( args.folder + "/*.jpg")
for file in files:
result = performDetect( imagePath = file, \
thresh = 0.25, \
configPath = "./yolo-tsukimachi.cfg", \
weightPath = "./yolo-tsukimachi.weights", \
metaPath = "./yolo-tsukimachi.data", \
showImage = True, \
makeImageOnly = True, \
initOnly = False)
if isinstance(result, list):
continue # Maybe image file format error
moon = False
for d in result["detections"]:
if d[0] == "night":
for d2 in result["detections"]:
if d2[0] == "stone":
if( d[2][0] > d2[2][0] - d2[2][2]/2 and \
d[2][0] < d2[2][0] + d2[2][2]/2 and \
d[2][1] > d2[2][1] - d2[2][3]/2 and \
d[2][1] < d2[2][1] + d2[2][3]/2 ):
moon = True
if moon == True:
io.imshow(result["image"])
io.show()
if __name__ == '__main__':
main()
はじめに、必要なモジュールをimportします。
import argparse import glob from skimage import io from darknet import performDetect
コマンドライン引数を解析するargparse、フォルダ内のファイルを列挙するためのglob、画像表示に使用するscikit-image(skimage)、そしてdarknetのPython用のラッパーdarknet.pyです。
メインの関数では、コマンドライン引数を解析し、指定されたフォルダ内の.jpgファイルのそれぞれについて、performDetect関数で検出処理を実行します。
parser = argparse.ArgumentParser(description='Find Tsukimachi-to images.')
parser.add_argument('folder', help='image folder')
args = parser.parse_args()
files = glob.glob( args.folder + "/*.jpg")
for file in files:
result = performDetect( imagePath = file, \
サブフォルダを再帰的に検索したい場合は、以下のようにglob()を呼び出します。
files = glob.glob( args.folder + "/**/*.jpg", recursive=True)
performDetect関数の引数は、順に
- 画像ファイルのパス
- 認識のしきい値
- .cfgファイルのパス
- .weightファイルのパス
- .dataファイルのパス
- 画像表示フラグ
- 画像生成のみフラグ
- 初期化のみフラグ
です。.cfgファイルと.dataファイルは学習時に使用したものをそのまま使用します。画像表示フラグと画像生成のみフラグの両方をTrueに設定すると、認識結果の画像が生成されますが、performDetect関数自身は表示処理を行わず、戻り値で画像を返します。
画像表示フラグがTrueの場合、performDetect関数の戻り値は以下のdict型です。
{
"detections": 認識結果のリスト
"image": 認識結果の画像
"caption": 画像のキャプション
}
認識結果は、以下のタプルのリストです。
('ラベル', 信頼度, (バウンディングボックスの中心X座標, バウンディングボックスの中心Y座標, バウンディングボックスの幅, バウンディングボックスの高さ))
画像ファイルのフォーマットによっては、performDetect関数の中でエラーとなり、dict型ではなくlist型が返されることがあるので、戻り値がlist型かどうかチェックします。
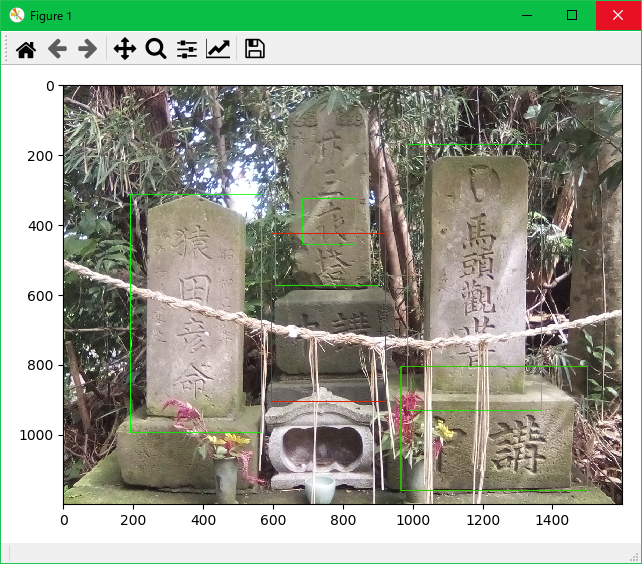
認識結果が得られたら、月待塔が写っているかどうかの判定をします。まず、外側のループでは「夜」の文字の認識結果を探します。見つかったら、今度は内側のループで石の認識結果を探します。「夜」の文字の中心座標が、石のバウンディングボックス内に含まれていれば、月待塔であると判断します。
for d in result["detections"]:
if d[0] == "night":
for d2 in result["detections"]:
if d2[0] == "stone":
if( d[2][0] > d2[2][0] - d2[2][2]/2 and \
d[2][0] < d2[2][0] + d2[2][2]/2 and \
d[2][1] > d2[2][1] - d2[2][3]/2 and \
d[2][1] < d2[2][1] + d2[2][3]/2 ):
moon = True
if moon == True:
io.imshow(result["image"])
io.show()
月待塔であれば、画像を表示します。
検索対象のフォルダ/ファイル名に日本語が含まれる場合は、darknet.pyの404行目のencode("ascii")をencode("CP932")に変更する必要があります。
detections = detect(netMain, metaMain, imagePath.encode("CP932"), thresh)
2020年6月14日 追記
学習に使用する画像ファイルを以下の4000枚に増加しました。
- ラベル付けの対象(月待塔が写っている)2000枚
- ラベル付けの対象外(石造物が写っていない)2000枚
ラベルの内訳は
- 石 2709件
- 夜 2032件
でした。
石造物の写っていない写真が学習データに含まれていない場合には、しばしば石造物以外の物を石と判定することがありましたが、そのようなことは、ほとんどなくなりました。
「夜」については、別の文字を「夜」と判定することがまだありますので、今後はそのような誤った判定をした画像を学習データに加え、さらに精度を高めたいと思います。