Linked Open Data チャレンジ Japan 2023では、「みんなで石仏調査 附 みんなで石仏調査LODテクニカルプレビュー」が最優秀賞を頂きました。石造物の参加型オープンデータのプロジェクト「みんなで石仏調査」と、そこで収集されたデータをLinked Open Dataとして公開する「みんなで石仏調査LODテクニカルプレビュー」をセットにしたものです。
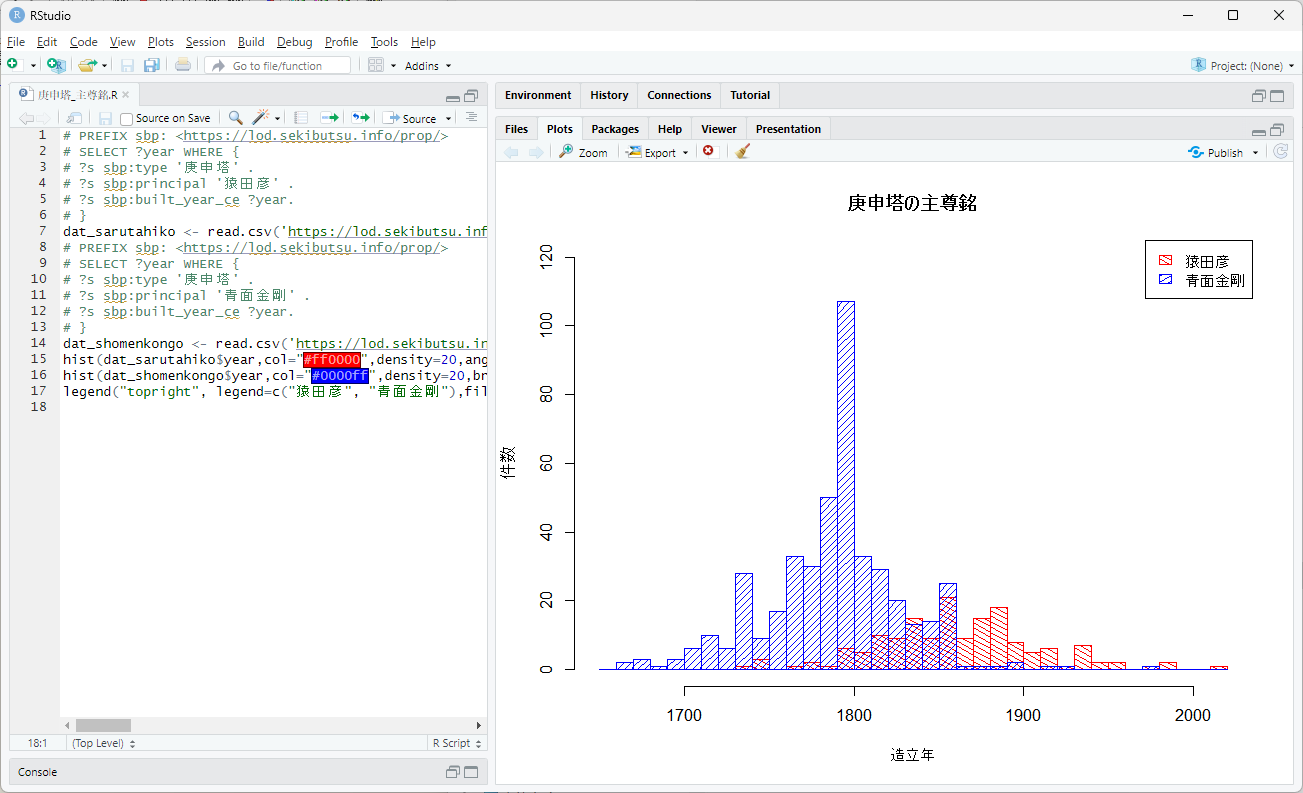
そこで、Linked Dataのクエリ言語であるSPARQLと、統計解析ソフトのRを使用して、みんなで石仏調査LODのデータを分析・可視化する方法について書きます。RStudio上で、このようなヒストグラムを表示するのがゴールです。
「データサイエンス」カテゴリーアーカイブ
学会発表のお知らせ
2023年2月18日(土)にオンラインで開催された第131回 人文科学とコンピュータ研究会発表会において、「武相自由民権LOD – Linked Dataによる再利用可能な歴史データベース作成の試み」と題して発表しました。

論文は情報学広場からダウンロードできます。
学会発表のお知らせ
2021年5月22日(土)にオンラインで開催された第126回 人文科学とコンピュータ研究発表会において、「深層学習を用いた石造物の検出と分類」と題して発表しました。

論文は情報学広場からダウンロードできます。
AIによるデータエンリッチメント
データの利活用において分析や可視化の技術も大切ですが、まずはデータそのものが重要であることは言うまでもありません。そこで注目されているのがデータクレンジングとデータエンリッチメントです。
データクレンジングでは、欠損や重複を修正したり表記の統一や正規化をすることによってデータの品質を向上させます。データエンリッチメントでは、元のデータに情報を付加してより有用なものに拡張します。
今回は、月待塔のデータを集める月待ビンゴプロジェクトの成果である月待塔オープンデータを対象としてデータエンリッチメントを実施します。月待塔オープンデータに画像ファイルそのものは含まれませんが、画像ファイルのURLは含まれています。そこで、URLから画像をダウンロードしてAIにより物体検出した結果を元データに追加し、拡張されたデータを分析することによって得られた知見を紹介します。
続きを読む
YOLOv5への移行
Darknet YOLOv4を使って機械学習を始め、「深層学習による石造物の分類」以来、いくつかのブログ記事を書いてきました。1ヶ月ほど前にYOLOv5に移行したところ、予想を遥かに上回る良好な結果を得ることができましたので、簡単にYOLOv5を紹介します。
特筆すべき点は、
- インストールが簡単(Pythonの環境があれば動作し、Visual Studioのような開発環境は不要)
- 検出処理が高速で精度も高い
です。また、YOLOv5はGPU(CUDA)なしで動作させることも可能です。