内容が古くなっている可能性がありますのでご注意下さい。
「雑草という名の草はない」という言葉がよく知られている一方で、道端に生えている草の多くは名前が知られていません。同じように、路傍に立つ古い石造物も、今となってはそれが何なのか知らない人が多くて残念です。
民間信仰に基づいて造立された石造物の分類は、専門家でも一筋縄ではいかないものです。それは、民間信仰そのものの成り立ちが、複雑な歴史的背景を持つことによります。
そこで、あまり深い所には立ち入らず、月待信仰に基づいて造立された月待塔について、画像から分類を試みます。月待塔は月待行事をおこなった「アタリ日」によって分類することができ、塔のどこかに「十九夜」や「二十三夜」のように刻まれているので、これらの文字によって容易に分類することができるのです。
今回構築したシステムで実際に二十三夜塔を認識させた例は以下のようになります。

「三夜」の上にある「サ」のような文字は「廿」です。二十三夜塔は、単に「三夜」と刻まれたり、「念三夜」「廿三夜」「二十三夜」「弐十三夜」と刻まれるなど、さまざまなパターンがありますが、今回は「三夜」の部分だけを認識させることとしました。
与えられた画像の中から、あらかじめ学習してある物体を検出する深層学習(ディープラーニング)の手法には、SSD(Single Shot MultiBox Detector)やYOLO(You Only Look Once)があります。今回はYOLOを利用することにします。また、YOLOの実装には、Keras/TensorFlow上で動作するkeras-yolo3もありますが、PythonではなくC言語で実装されたDarknetが速くて良さそうなので利用します。
以下のような環境を構築しました。
- OS : Windows 10
- GPU : NVIDIA GeForce GTX1660 Super
- CUDA : CUDA Toolkit 10.2
- cuDNN : cuDNN v7.6.5 for CUDA 10.2
- OpenCV : opencv-3.4.10
- 開発環境 : Visual Studio Community 2017
開発環境が挙げられているということは、GitHubで公開されているソースコードからビルドする必要があるということです。ビルド方法はGitHubにも書かれていますが、Qiitaにあるこちらの記事が分かりやすいので、ここでは説明は省きます。上記の環境では、darknet.vcxprojでcuda 10.0を参照している箇所をcuda 10.2に変更する必要がありました。
学習用データの準備
さて、いよいよここからが本題です。石造物を対象とした学習済みモデルは世の中にまだありませんので、自分で作らなければなりません。そのためには大量の画像が必要です。
月待塔に関しては、月待ビンゴプロジェクトで集められたデータがGitHubでオープンデータとして公開されています。その中に画像ファイル自体は含まれていませんが、CSVファイルには画像ファイルのURLが含まれているので、これを使用すれば大量の月待塔画像をダウンロードすることができます。
画像が用意できたら、次はアノテーションを行います。アノテーションとは、画像の中で認識させたい領域を指定してラベルを付ける作業です。これには、マイクロソフトのVoTT(Visual Object Tagging Tool)というツールを使用しました。

上の例では、「三夜」と刻まれている領域を指定して「sanya」のラベルを付けています。同様に「九夜」に「kuya」、「六夜」に「rokuya」のラベルを付けました。今回の例では1画像あたり1つのラベルになりましたが、もちろん1つの画像に複数種類のラベルを付けることもできます。
今回は計888枚の画像にラベルを付けました。内訳は以下のとおりです。
- sanya : 515
- kuya : 334
- rokuya : 39
他と比べて六夜が少ないのが気になります。
VoTTは非常に使いやすいツールですが、現バージョンはYOLO用のデータファイルを生成できないという問題があります。そこで、VoTTからPascal VOC形式でエクスポートしたデータファイルをこちらのスクリプトでYOLO用に変換しました。
変換してできた.txtファイルは対応する.jpgファイルと一緒に
C:\darknet\build\darknet\x64\data\
の下に作成したフォルダにコピーします。
設定ファイルの作成と学習の実行
さらにいくつかの設定ファイルの作成が必要になります。GitHubのこちらで詳しく説明されています。
今回は3つのクラスに分類するため、.cfgファイルでは、
max_batches = 6000 # classes*2000 steps=4800,5400 # 80% and 90% of max_batches
を指定しました。また、最初の実行で「CUDA Out of Memory」というエラーが出たため、
batch=16 subdivisions=16 width=320 height=320
に変更しました。
.namesファイルには、今回の分類に使用する3つのクラス
sanya kuya rokuya
を記述しました。
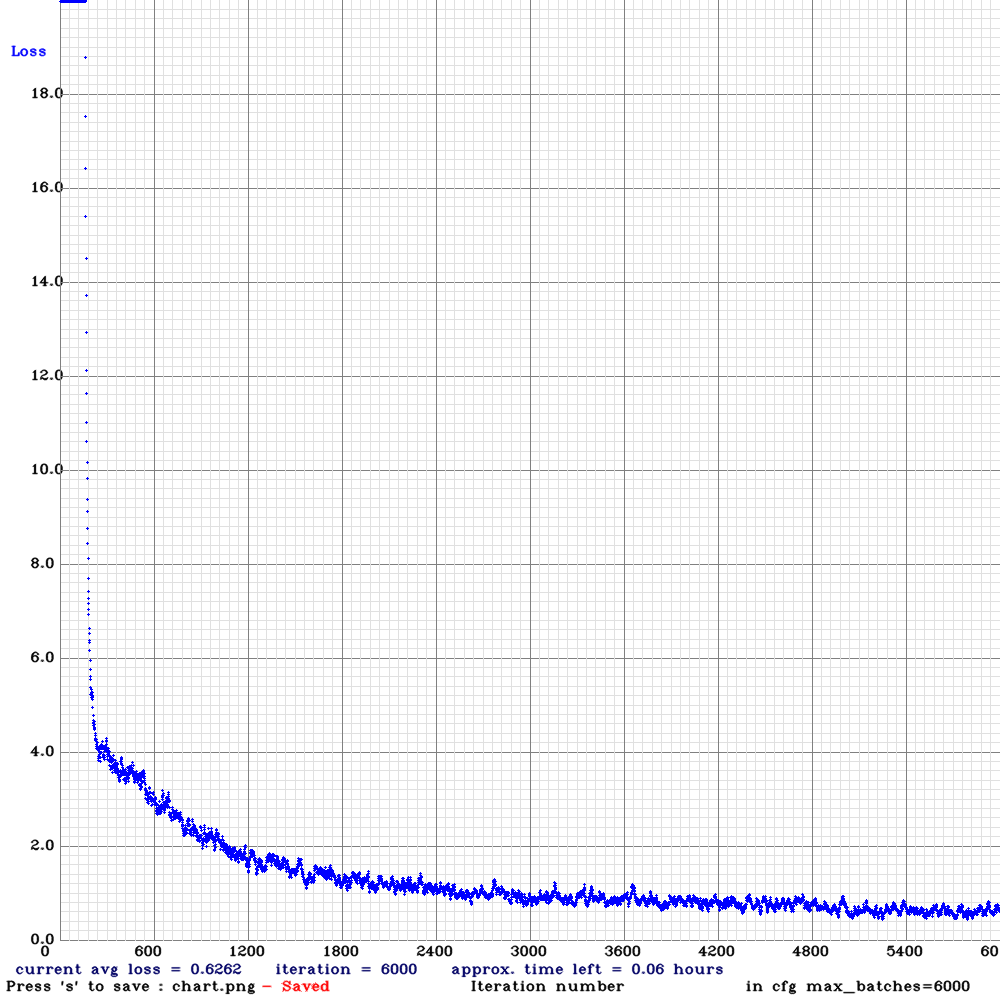
設定ファイルと事前学習済みモデルのファイルを指定して darknet.exe detector train コマンドを起動すると、別ウィンドウに学習曲線が表示されます。
今回は2時間半ほどで終了し、終了時の学習曲線は以下のようになりました。
実験結果
設定ファイルと今回作成したモデルと画像ファイルを指定して darknet.exe detector test コマンドを起動すると、別ウィンドウに画像が表示され、その上に認識結果を示す矩形とラベルが表示されます。二十三夜塔での実験結果は冒頭に示したとおりです。
十九夜塔でもkuyaが認識されています。

十九夜塔には、中央に大きく如意輪観音が彫られ、舟形光背の部分に小さく文字が刻まれるタイプの刻像塔が多くみられます。そのような塔でもkuyaを認識することができました。

学習データの少なかった「六夜」(実際には十六夜または二十六夜/廿六夜)でも、期待通りrokuyaが認識されました。

月待塔には「二十二夜塔」もありますが、二と三では紛らわしいので今回は学習データから外しておきました。試しに二十二夜塔を認識させてみたところ、予想通りsanyaが認識されました。

また、三の字が「弎 」になっている場合は、sanyaとkuyaが認識されました。

コマンドを起動したコンソールに表示された信頼度は、
- kuya: 46%
- sanya: 79%
でした。
2020年5月27日 追記
画像を1390枚に増やし、「二夜」と顔にラベルを付けました。今回は、1つの画像に1つのラベルとは限りません。内訳は以下のとおりです。
- sanya : 572
- kuya : 485
- rokuya : 49
- niya : 93
- face : 625
前回、sanyaと認識されていた二十二夜塔は、正しくniyaと認識されました。

十九夜の刻像塔では、kuyaのほかに如意輪観音の顔も認識されました。
